בין האינדיקטורים הרבים המשמשים בסטטיסטיקה, יש צורך להדגיש את חישוב השונות. יש לציין שביצוע חישוב זה ידני הוא משימה מייגעת למדי. למרבה המזל, ישנן פונקציות באקסל המאפשרות לך להפוך את הליך החישוב לאוטומטי. בואו לגלות את האלגוריתם לעבודה עם הכלים האלה.
פיזור הוא אינדיקטור לשונות, שהוא הריבוע הממוצע של סטיות מהציפייה המתמטית. לפיכך, הוא מבטא את התפשטות המספרים על הממוצע. חישוב הפיזור יכול להתבצע הן עבור האוכלוסייה הכללית והן עבור המדגם.
שיטה 1: חישוב על האוכלוסייה הכללית
כדי לחשב מחוון זה ב-Excel עבור האוכלוסייה הכללית, נעשה שימוש בפונקציה DISP.G. התחביר לביטוי זה הוא כדלקמן:
DISP.G(Number1;Number2;...)
בסך הכל, ניתן להחיל בין 1 ל-255 ארגומנטים. טיעונים יכולים להיות גם ערכים מספריים וגם הפניות לתאים שבהם הם כלולים.
בואו נראה כיצד לחשב ערך זה עבור טווח של נתונים מספריים.


שיטה 2: חישוב לדוגמה
בניגוד לחישוב הערך לכלל האוכלוסייה, בחישוב המדגם לא מצוין המכנה סה"כמספרים, אבל אחד פחות. זה נעשה על מנת לתקן את השגיאה. Excel לוקח בחשבון את הניואנס הזה בפונקציה מיוחדת המיועדת לסוג זה של חישוב - DISP.V. התחביר שלו מיוצג על ידי הנוסחה הבאה:
VAR.B(מספר1;מספר2;...)
גם מספר הארגומנטים, כמו בפונקציה הקודמת, יכול לנוע בין 1 ל-255.


כפי שאתה יכול לראות, תוכנית Excel מסוגלת להקל מאוד על חישוב השונות. נתון זה יכול להיות מחושב על ידי היישום הן עבור האוכלוסייה והן עבור המדגם. במקרה זה, כל פעולות המשתמש מצטמצמות למעשה רק לציון טווח המספרים שיש לעבד, ואקסל עושה את העבודה העיקרית בעצמו. כמובן, זה יחסוך כמות משמעותית של זמן למשתמשים.
פְּזִירָהמשתנה רנדומלי- מדד לפיזור נתון משתנה רנדומלי, כלומר היא סטיותמתוך ציפייה מתמטית. בסטטיסטיקה, הסימון (סיגמא בריבוע) משמש לעתים קרובות לציון שונות. השורש הריבועי של השונות נקרא סטיית תקןאו ממרח סטנדרטי. סטיית התקן נמדדת באותן יחידות כמו המשתנה האקראי עצמו, והשונות נמדדת בריבועים של אותה יחידה.
למרות שמאוד נוח להשתמש בערך אחד בלבד (כגון ממוצע או מצב וחציון) כדי להעריך את המדגם כולו, גישה זו יכולה בקלות להוביל למסקנות שגויות. הסיבה למצב זה אינה נעוצה בערך עצמו, אלא בעובדה שערך אחד אינו משקף בשום אופן את התפשטות ערכי הנתונים.
לדוגמה, בדוגמה:
הממוצע הוא 5.
עם זאת, אין אלמנט במדגם עצמו עם ערך של 5. ייתכן שיהיה עליך לדעת עד כמה כל רכיב במדגם קרוב לערך הממוצע שלו. או, במילים אחרות, אתה צריך לדעת את השונות של הערכים. לדעת באיזו מידה הנתונים השתנו, אתה יכול לפרש טוב יותר ערך ממוצע, חֲצִיוֹןו אופנה. מידת השינוי בערכי המדגם נקבעת על ידי חישוב השונות וסטיית התקן שלהם.
פיזור ו שורש ריבועישל השונות, הנקראת סטיית התקן, מאפיינים את הסטייה הממוצעת מהממוצע של המדגם. בין שתי הכמויות הללו, החשובה ביותר היא סטיית תקן. ערך זה יכול להיות מיוצג כמרחק הממוצע שבו האלמנטים נמצאים מהאלמנט האמצעי של המדגם.
קשה לפרש בצורה משמעותית פיזור. עם זאת, השורש הריבועי של ערך זה הוא סטיית התקן ומתאים לפרשנות.
סטיית התקן מחושבת על ידי תחילה קביעת השונות ולאחר מכן חישוב השורש הריבועי של השונות.
לדוגמה, עבור מערך הנתונים המוצג באיור, יתקבלו הערכים הבאים:

תמונה 1
כאן, הממוצע של ההבדלים בריבוע הוא 717.43. כדי לקבל את סטיית התקן, נותר רק לקחת את השורש הריבועי של מספר זה.
התוצאה תהיה בערך 26.78.
יש לזכור שסטיית התקן מתפרשת כמרחק הממוצע שבו האלמנטים נמצאים מממוצע המדגם.
סטיית התקן מראה עד כמה הממוצע מתאר את המדגם כולו.
נניח שאתה ראש מחלקת ייצור להרכבת PC. הדוח הרבעוני אומר שהתפוקה ברבעון האחרון הייתה 2500 מחשבים אישיים. האם זה רע או טוב? ביקשת (או שכבר קיימת עמודה זו בדוח) להציג את סטיית התקן עבור נתונים אלו בדוח. מספר סטיית התקן, למשל, הוא 2000. מתברר לך, כראש המחלקה, שקו הייצור זקוק לשליטה טובה יותר (סטיות גדולות מדי במספר המחשבים המורכבים).
נזכיר שכאשר סטיית התקן גדולה, הנתונים מפוזרים באופן נרחב סביב הממוצע, וכאשר סטיית התקן קטנה, הם מתקבצים קרוב לממוצע.
ארבעה סטטיסטיים פונקציות DISP(), VARP(), STDEV() ו- STDEV() - נועד לחשב את השונות וסטיית התקן של מספרים בטווח של תאים. לפני שתוכל לחשב את השונות וסטיית התקן של מערך נתונים, עליך לקבוע אם הנתונים מייצגים את האוכלוסייה או מדגם של האוכלוסייה. במקרה של מדגם מהאוכלוסייה הכללית, יש להשתמש בפונקציות VARP() ו-STDEV() ובמקרה של האוכלוסייה הכללית, יש להשתמש בפונקציות VARP() ו-STDEV():
| אוּכְלוֹסִיָה | פוּנקצִיָה |
 | VARP() |
 | STDLONG() |
| לִטעוֹם | |
 | VARI() |
 | STDEV() |
השונות (כמו גם סטיית התקן), כפי שציינו, מציינת את המידה שבה הערכים הכלולים במערך הנתונים מפוזרים סביב הממוצע האריתמטי.
ערך קטן של השונות או סטיית התקן מצביע על כך שכל הנתונים מרוכזים סביב הממוצע האריתמטי, וערך גדול של ערכים אלו מצביע על כך שהנתונים מפוזרים על פני מגוון רחב של ערכים.
השונות די קשה לפרש בצורה משמעותית (מה המשמעות של ערך קטן, ערך גדול?). ביצועים משימות 3יאפשר לך חזותית, על גרף, להראות את משמעות השונות עבור מערך נתונים.
משימות
· תרגיל 1.
· 2.1. תן את המושגים: שונות וסטיית תקן; ייעודם הסמלי בעיבוד נתונים סטטיסטיים.
· 2.2. ערכו דף עבודה בהתאם לתמונה 1 ובצעו את החישובים הדרושים.
· 2.3. תנו את הנוסחאות הבסיסיות המשמשות בחישובים
· 2.4. הסבר את כל הסימון ( , , )
· 2.5. הסבר את המשמעות המעשית של מושג השונות וסטיית התקן.
משימה 2.
1.1. תנו את המושגים: אוכלוסייה כללית ומדגם; תוחלת מתמטית וממוצע אריתמטי של ייעודם הסמלי בעיבוד נתונים סטטיסטיים.
1.2. בהתאם לתמונה 2, ערכו דף עבודה וערכו חישובים.
1.3. תנו את הנוסחאות הבסיסיות המשמשות בחישובים (לכלל האוכלוסייה ולמדגם).

איור 2
1.4. הסבר מדוע ניתן לקבל ערכים כאלה של אמצעים אריתמטיים בדגימות כמו 46.43 ו-48.78 (ראה נספח קובץ). לְהַסִיק.
משימה 3.
ישנן שתי דוגמאות עם סט נתונים שונה, אך הממוצע עבורן יהיה זהה:

איור 3
3.1. ערכו דף עבודה בהתאם לתמונה 3 ובצעו את החישובים הדרושים.
3.2. תן את נוסחאות החישוב הבסיסיות.
3.3. בנה גרפים בהתאם לתמונות 4, 5.
3.4. הסבר את התלות שנוצרה.
3.5. בצע חישובים דומים עבור שתי הדגימות הללו.
מדגם ראשוני 11119999
בחר את הערכים של המדגם השני כך שהממוצע האריתמטי עבור המדגם השני יהיה זהה, למשל:

בחר את הערכים עבור המדגם השני בעצמך. סדרו את החישובים והשרטוטים כמו איורים 3, 4, 5. הצג את הנוסחאות העיקריות ששימשו בחישובים.
הסיק את המסקנות המתאימות.
יש להציג את כל המשימות בצורה של דו"ח עם כל הנתונים הדרושים, גרפים, נוסחאות והסברים קצרים.
הערה: יש להסביר את בניית הגרפים באמצעות דמויות והסברים קצרים.
תורת ההסתברות היא ענף מיוחד במתמטיקה הנלמד רק על ידי תלמידי מוסדות להשכלה גבוהה. האם אתה אוהב חישובים ונוסחאות? האם אינך חושש מהסיכויים של היכרות עם ההתפלגות הנורמלית, האנטרופיה של האנסמבל, הציפייה המתמטית והשונות של משתנה מקרי בדיד? אז הנושא הזה יעניין אותך מאוד. בואו נכיר כמה מהמושגים הבסיסיים החשובים ביותר של חלק זה של המדע.
בואו נזכור את היסודות
גם אם אתה זוכר את המושגים הפשוטים ביותר של תורת ההסתברות, אל תזניח את הפסקאות הראשונות של המאמר. העובדה היא שללא הבנה ברורה של היסודות, לא תוכל לעבוד עם הנוסחאות שנדונו להלן.
אז, יש איזה אירוע אקראי, איזה ניסוי. כתוצאה מהפעולות שבוצעו, אנו יכולים לקבל מספר תוצאות – חלקן שכיחות יותר, אחרות פחות שכיחות. ההסתברות לאירוע היא היחס בין מספר התוצאות שהתקבלו בפועל מסוג אחד ל מספר כוללאפשרי. רק אם אתה יודע את ההגדרה הקלאסית של מושג זה, אתה יכול להתחיל ללמוד את הציפייה המתמטית ואת הפיזור של משתנים אקראיים רציפים.
מְמוּצָע
עוד בבית הספר, בשיעורי מתמטיקה, התחלת לעבוד עם הממוצע החשבוני. מושג זה נמצא בשימוש נרחב בתורת ההסתברות, ולכן לא ניתן להתעלם ממנו. העיקר מבחינתנו הרגע הזההוא שנפגוש אותו בנוסחאות לתוחלת ושונות מתמטית של משתנה אקראי.

יש לנו רצף של מספרים ורוצים למצוא את הממוצע האריתמטי. כל מה שנדרש מאיתנו הוא לסכם את כל מה שקיים ולחלק במספר האלמנטים ברצף. נקבל מספרים מ-1 עד 9. סכום היסודות יהיה 45, ונחלק את הערך הזה ב-9. תשובה: - 5.
פְּזִירָה
במונחים מדעיים, השונות היא הריבוע הממוצע של הסטיות של ערכי התכונה שהושגו מהממוצע האריתמטי. אחד מסומן באות לטינית גדולה D. מה צריך כדי לחשב אותו? עבור כל רכיב ברצף, אנו מחשבים את ההפרש בין המספר הזמין לממוצע האריתמטי ומריבוע אותו. יהיו בדיוק כמה ערכים שיכולים להיות תוצאות לאירוע שאנו שוקלים. לאחר מכן, נסכם את כל מה שהתקבל ונחלק במספר האלמנטים ברצף. אם יש לנו חמש תוצאות אפשריות, חלק בחמש.

לשונות יש גם תכונות שאתה צריך לזכור כדי ליישם אותה בעת פתרון בעיות. לדוגמה, אם המשתנה האקראי גדל ב-X פעמים, השונות גדלה פי X מהריבוע (כלומר, X*X). זה אף פעם לא פחות מאפס ואינו תלוי בהזזת ערכים בערך שווה למעלה או למטה. כמו כן, עבור ניסויים עצמאיים, השונות של הסכום שווה לסכום השונות.
כעת אנו בהחלט צריכים לשקול דוגמאות לשונות של משתנה אקראי בדיד והתוחלת המתמטית.
נניח שאנו מריצים 21 ניסויים ומקבלים 7 תוצאות שונות. צפינו בכל אחד מהם, בהתאמה, 1,2,2,3,4,4 ו-5 פעמים. מה תהיה השונות?
ראשית, אנו מחשבים את הממוצע האריתמטי: סכום היסודות, כמובן, הוא 21. נחלק אותו ב-7, ונקבל 3. כעת נחסר 3 מכל מספר ברצף המקורי, ריבוע כל ערך ונחבר את התוצאות יחדיו. . מסתבר 12. כעת נותר לנו לחלק את המספר במספר האלמנטים, וכך נראה, זה הכל. אבל יש מלכוד! בואו נדון בזה.
תלוי במספר הניסויים
מסתבר שכאשר מחשבים את השונות, המכנה יכול להיות אחד משני מספרים: או N או N-1. כאן N הוא מספר הניסויים שבוצעו או מספר האלמנטים ברצף (שזה בעצם אותו דבר). במה זה תלוי?

אם מספר הבדיקות נמדד במאות אז עלינו לשים במכנה N. אם ביחידות אז N-1. המדענים החליטו לשרטט את הגבול באופן סמלי למדי: היום הוא עובר על המספר 30. אם ערכנו פחות מ-30 ניסויים, נחלק את הכמות ב-N-1, ואם יותר, אז ב-N.
מְשִׁימָה
נחזור לדוגמא שלנו לפתרון בעיית השונות והציפיות. קיבלנו מספר ביניים של 12, אותו היה צריך לחלק ב-N או ב-N-1. מכיוון שערכנו 21 ניסויים שהם פחות מ-30, נבחר באפשרות השנייה. אז התשובה היא: השונות היא 12/2 = 2.
ערך צפוי
הבה נעבור למושג השני, שעלינו לשקול במאמר זה. התוחלת המתמטית היא תוצאה של הוספת כל התוצאות האפשריות כפול ההסתברויות המתאימות. חשוב להבין שהערך המתקבל, כמו גם תוצאת חישוב השונות, מתקבל רק פעם אחת עבור כל המשימה, לא משנה כמה תוצאות היא מחשיבה.

נוסחת הציפייה המתמטית היא פשוטה למדי: אנו לוקחים את התוצאה, מכפילים אותה בהסתברות שלה, מוסיפים אותו הדבר עבור התוצאה השנייה, השלישית וכו'. כל מה שקשור למושג זה קל לחישוב. לדוגמה, סכום הציפיות המתמטי שווה לציפיות המתמטיות של הסכום. הדבר נכון גם לגבי העבודה. לא כל כמות בתורת ההסתברות מאפשרת לבצע פעולות פשוטות כאלה. בואו ניקח משימה ונחשב את ערכם של שני מושגים שלמדנו בבת אחת. בנוסף, דעתנו הוסחה על ידי תיאוריה – הגיע הזמן לתרגל.
עוד דוגמה אחת
הרצנו 50 ניסויים וקיבלנו 10 סוגים של תוצאות - מספרים 0 עד 9 - המופיעים באחוזים משתנים. אלה הם, בהתאמה: 2%, 10%, 4%, 14%, 2%, 18%, 6%, 16%, 10%, 18%. נזכיר שכדי לקבל את ההסתברויות, עליך לחלק את ערכי האחוזים ב-100. לפיכך, אנו מקבלים 0.02; 0.1 וכו' הבה נציג דוגמה לפתרון הבעיה עבור השונות של משתנה מקרי והתוחלת המתמטית.
אנו מחשבים את הממוצע האריתמטי באמצעות הנוסחה הזכורה לנו מבית הספר היסודי: 50/10 = 5.
עכשיו בואו נתרגם את ההסתברויות למספר התוצאות "בחתיכות" כדי שיהיה נוח יותר לספור. נקבל 1, 5, 2, 7, 1, 9, 3, 8, 5 ו-9. מחסירים את הממוצע האריתמטי מכל ערך שהתקבל, ולאחר מכן נריבוע כל אחת מהתוצאות שהתקבלו. ראה כיצד לעשות זאת עם האלמנט הראשון כדוגמה: 1 - 5 = (-4). עוד: (-4) * (-4) = 16. עבור ערכים אחרים, בצע את הפעולות הללו בעצמך. אם עשית הכל נכון, אז לאחר הוספת הכל אתה מקבל 90.

נמשיך בחישוב השונות והממוצע על ידי חלוקת 90 ב-N. מדוע נבחר ב-N ולא ב-N-1? זה נכון, כי מספר הניסויים שבוצעו עולה על 30. אז: 90/10 = 9. קיבלנו את הפיזור. אם אתה מקבל מספר אחר, אל ייאוש. סביר להניח שעשית טעות בנאלית בחישובים. תבדוק שוב את מה שכתבת, ובטוח שהכל יסתדר.
לבסוף, נזכיר את נוסחת הציפייה המתמטית. לא ניתן את כל החישובים, נכתוב רק את התשובה שאיתה תוכל לבדוק לאחר השלמת כל ההליכים הנדרשים. הערך הצפוי יהיה 5.48. אנו רק זוכרים כיצד לבצע פעולות, באמצעות הדוגמה של האלמנטים הראשונים: 0 * 0.02 + 1 * 0.1 ... וכן הלאה. כפי שאתה יכול לראות, אנו פשוט מכפילים את ערך התוצאה בהסתברות שלה.
חֲרִיגָה
מושג נוסף הקשור קשר הדוק לפיזור וציפייה מתמטית הוא סטיית התקן. זה מסומן או באותיות sd הלטיניות, או באותיות קטנות היווניות "סיגמה". מושג זה מראה כיצד, בממוצע, ערכים חורגים מהתכונה המרכזית. כדי למצוא את ערכו, עליך לחשב את השורש הריבועי של השונות.

אם אתה מתווה התפלגות נורמלית ורוצה לראות ישירות עליה סטיית תקן, ניתן לעשות זאת בכמה שלבים. קח חצי מהתמונה משמאל או מימין למצב (ערך מרכזי), צייר מאונך לציר האופקי כך ששטחי הדמויות המתקבלות יהיו שווים. ערך הקטע בין אמצע ההתפלגות להשלכה המתקבלת על הציר האופקי יהיה סטיית התקן.
תוֹכנָה
כפי שניתן לראות מתיאורי הנוסחאות והדוגמאות שהוצגו, חישוב השונות והתוחלת המתמטית אינו ההליך הקל ביותר מבחינה אריתמטית. כדי לא לבזבז זמן, זה הגיוני להשתמש בתוכנית המשמשת גבוה יותר מוסדות חינוך- זה נקרא "R". יש לו פונקציות המאפשרות לך לחשב ערכים עבור מושגים רבים מסטטיסטיקה ותורת ההסתברות.
לדוגמה, אתה מגדיר וקטור של ערכים. זה נעשה באופן הבא: וקטור<-c(1,5,2…). Теперь, когда вам потребуется посчитать какие-либо значения для этого вектора, вы пишете функцию и задаете его в качестве аргумента. Для нахождения дисперсии вам нужно будет использовать функцию var. Пример её использования: var(vector). Далее вы просто нажимаете «ввод» и получаете результат.
סוף כל סוף
פיזור וציפייה מתמטית הם שבלעדיהם קשה לחשב שום דבר בעתיד. בקורס העיקרי של הרצאות באוניברסיטאות הם נחשבים כבר בחודשים הראשונים ללימוד הנושא. דווקא בגלל חוסר ההבנה של המושגים הפשוטים הללו וחוסר היכולת לחשב אותם, סטודנטים רבים מתחילים מיד לפגר בתכנית ובהמשך מקבלים בתום המפגש ציונים גרועים, מה שמונע מהם מלגות.
תרגל לפחות שבוע במשך חצי שעה ביום, פתרון משימות דומות לאלו המוצגות במאמר זה. לאחר מכן, בכל מבחן תורת ההסתברות, תתמודד עם דוגמאות ללא טיפים מיותרים ודפי רמאות.
לצד חקר השונות של תכונה בכל האוכלוסייה כולה, יש צורך פעמים רבות להתחקות אחר השינויים הכמותיים בתכונה בקבוצות שאליהן מחולקת האוכלוסייה, וכן בין קבוצות. מחקר זה של שונות מושג על ידי חישוב וניתוח סוגים שונים של שונות.
הבחנה בין פיזור כולל, בין-קבוצתי ותוך-קבוצתי.
השונות הכוללת σ 2מודד את השונות של תכונה על פני כל האוכלוסייה בהשפעת כל הגורמים שגרמו לשונות זו,.
שונות בין קבוצות (δ) מאפיינת שונות שיטתית, כלומר. הבדלים בגודל התכונה הנחקרת, הנובעים בהשפעת גורם התכונה העומד בבסיס הקיבוץ. זה מחושב לפי הנוסחה: 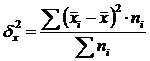 .
.
שונות בתוך הקבוצה (σ)משקף וריאציה אקראית, כלומר. חלק מהשונות המתרחשת תחת השפעת גורמים לא ברורים ואינה תלויה בגורם התכונה שבבסיס הקיבוץ. זה מחושב לפי הנוסחה: 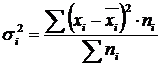 .
.
ממוצע של שונות בתוך הקבוצה:  .
.
יש חוק שמקשר בין 3 סוגי פיזור. השונות הכוללת שווה לסכום הממוצע של השונות התוך-קבוצתית והבין-קבוצתית: ![]() .
.
יחס זה נקרא כלל הוספת שונות.
בניתוח נעשה שימוש נרחב במדד שהוא שיעור השונות בין קבוצות בשונות הכוללת. זה נושא את השם מקדם קביעה אמפירי (η 2): .
השורש הריבועי של מקדם הקביעה האמפירי נקרא יחס מתאם אמפירי (η):
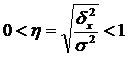 .
.
הוא מאפיין את השפעת התכונה העומדת בבסיס הקיבוץ על השונות של התכונה המתקבלת. יחס המתאם האמפירי משתנה בין 0 ל-1.
נראה את השימוש המעשי שלו בדוגמה הבאה (טבלה 1).
דוגמה מס' 1. טבלה 1 - פריון עבודה של שתי קבוצות עובדים של אחת מהסדנאות של עמותת "ציקלון"
חשב את הממוצעים והשונות הכולל והקבוצה:
הנתונים הראשוניים לחישוב הממוצע של הפיזור התוך-קבוצתי והבין-קבוצתי מוצגים בטבלה. 2.
שולחן 2
חישוב ו-δ 2 עבור שתי קבוצות עובדים.
|
קבוצות עובדים | מספר עובדים, פרס. | ממוצע, נתון/משמרת. | פְּזִירָה |
| עבר הכשרה טכנית | 5 | 95 | 42,0 |
| לא מאומן טכנית | 5 | 81 | 231,2 |
| כל העובדים | 10 | 88 | 185,6 |
 .
.
שונות בין קבוצות
השונות הכוללת:
לפיכך, יחס המתאם האמפירי:.
יחד עם וריאציה של תכונות כמותיות, ניתן להבחין גם וריאציה של תכונות איכותיות. מחקר זה של שונות מושגת על ידי חישוב סוגי השונות הבאים:
השונות התוך-קבוצתית של המניה נקבעת על ידי הנוסחה
איפה n i– מספר היחידות בקבוצות נפרדות.שיעור התכונה הנחקרת באוכלוסיה כולה, אשר נקבע על ידי הנוסחה:
שלושת סוגי הפיזור קשורים זה לזה באופן הבא:
יחס השונות הזה נקרא משפט הוספת השונות של תכונה.
סוגי פיזור:
שונות מוחלטתמאפיין את השונות של התכונה של כלל האוכלוסייה בהשפעת כל אותם גורמים שגרמו לשונות זו. ערך זה נקבע על ידי הנוסחה
היכן הממוצע האריתמטי הכללי של כל אוכלוסיית המחקר.
שונות ממוצעת בתוך הקבוצהמצביע על וריאציה אקראית שעלולה להיווצר בהשפעת גורמים שאינם מנוהלים ואינה תלויה בגורם האופייני העומד בבסיס הקיבוץ. השונות הזו מחושבת באופן הבא: ראשית, השונות עבור קבוצות בודדות מחושבות (), לאחר מכן מחושבת השונות הממוצעת בתוך הקבוצה:
 כאשר n i הוא מספר היחידות בקבוצה
כאשר n i הוא מספר היחידות בקבוצה
שונות בין קבוצות(פיזור האמצעים הקבוצתיים) מאפיין שונות שיטתית, כלומר. הבדלים בערכה של התכונה הנחקרת, הנובעים בהשפעת גורם התכונה, שהוא הבסיס לקיבוץ.

איפה הערך הממוצע לקבוצה נפרדת.
כל שלושת סוגי השונות קשורים זה בזה: השונות הכוללת שווה לסכום השונות הבין-קבוצתית הממוצעת והשונות הבין-קבוצתית:
![]()
נכסים:
25 שיעורי שונות יחסית
|
גורם תנודה |
|
|
סטייה ליניארית יחסית |
|
|
מקדם השונות |
|
Coef. Osc. Oמשקף את התנודה היחסית של הערכים הקיצוניים של התכונה סביב הממוצע. Rel. לין. כבוי. מאפיין את חלקו של הערך הממוצע של סימן הסטיות המוחלטות מהערך הממוצע. Coef. וריאציה היא המדד הנפוץ ביותר של וריאציה המשמש להערכת האופייניות של ממוצעים.
בסטטיסטיקה, אוכלוסיות עם מקדם שונות גדול מ-30-35% נחשבות להטרוגניות.
סדירות סדרת הפצה. רגעי הפצה. אינדיקטורים של טופס הפצה
בסדרות וריאציות, יש קשר בין תדרים וערכים של תכונה משתנה: עם עלייה בתכונה, ערך התדר עולה תחילה לגבול מסוים, ואז יורד. שינויים כאלה נקראים דפוסי הפצה.
צורת ההפצה נחקרת באמצעות אינדיקטורים של אסימטריה וקורטוזיס. בעת חישוב אינדיקטורים אלה, נעשה שימוש ברגעי התפלגות.
הרגע של הסדר ה-k הוא הממוצע של דרגות ה-k של הסטיות של הווריאציות של ערכי התכונה מערך קבוע כלשהו. סדר הרגע נקבע לפי הערך k. כאשר מנתחים סדרות וריאציות, הם מסתפקים בחישוב הרגעים של ארבעת הסדרים הראשונים. בעת חישוב רגעים, ניתן להשתמש בתדרים או בתדרים כשקולות. בהתאם לבחירה בערך קבוע, ישנם רגעים ראשוניים, מותנים ומרכזיים.
אינדיקטורים של טופס הפצה:
אָסִימֵטְרִיָה(As) אינדיקטור המאפיין את מידת אסימטריית ההתפלגות .

לכן, עם הטיה שלילית (ביד שמאל).  . עם אסימטריה חיובית (בצד ימין).
. עם אסימטריה חיובית (בצד ימין).  .
.
ניתן להשתמש ברגעים מרכזיים לחישוב אסימטריה. לאחר מכן:
 ,
,
איפה μ 3 הוא הרגע המרכזי של הסדר השלישי.
- קורטוזיס (E ל ) מאפיין את התלולות של גרף הפונקציה בהשוואה להתפלגות הנורמלית עם אותו חוזק וריאציה:
 ,
,
כאשר μ 4 הוא הרגע המרכזי של הסדר הרביעי.
חוק הפצה רגילה
עבור התפלגות נורמלית (התפלגות גאוסית), לפונקציית ההתפלגות יש את הצורה הבאה:


תוחלת - סטיית תקן
ההתפלגות הנורמלית היא סימטרית ומאופיינת בקשר הבא: Xav=Me=Mo
הקורטוזיס של ההתפלגות הנורמלית הוא 3 והעקה היא 0.
עקומת ההתפלגות הנורמלית היא מצולע (קו ישר סימטרי בצורת פעמון)
סוגי פיזור. כלל להוספת שונות. מהות מקדם הקביעה האמפירי.
אם האוכלוסייה הראשונית מחולקת לקבוצות לפי תכונה חיונית כלשהי, אזי מחושבים סוגי הפיזור הבאים:
השונות הכוללת של האוכלוסייה המקורית:
היכן הוא הערך הממוצע הכולל של האוכלוסייה המקורית; f הוא התדירות של האוכלוסייה המקורית. השונות הכוללת מאפיינת את הסטייה של הערכים האישיים של התכונה מהערך הממוצע הכולל של האוכלוסייה המקורית.
שונות תוך קבוצתית:
כאשר j הוא מספר הקבוצה; הוא הערך הממוצע בכל קבוצה j-ה; הוא התדירות של הקבוצה j-th. שונות תוך קבוצתית מאפיינות את הסטייה של הערך האישי של תכונה בכל קבוצה מהממוצע הקבוצתי. מכל הפיזור התוך-קבוצתי, הממוצע מחושב לפי הנוסחה:, היכן הוא מספר היחידות בכל קבוצה j-th.
שונות בין קבוצות:
פיזור בין קבוצות מאפיין את הסטייה של ממוצעי הקבוצה מהממוצע הכולל של האוכלוסייה המקורית.
כלל הוספת שונותהוא שהשונות הכוללת של האוכלוסייה המקורית צריכה להיות שווה לסכום הבין-קבוצה והממוצע של השונות התוך-קבוצתית:
מקדם קביעה אמפירימראה את הפרופורציה של השונות של התכונה הנחקרת, עקב השונות של תכונת הקיבוץ, ומחושבת לפי הנוסחה:
שיטת התייחסות מאפס מותנה (שיטת מומנטים) לחישוב הממוצע והשונות
חישוב הפיזור בשיטת המומנטים מבוסס על שימוש בנוסחה ומאפיינים 3 ו-4 של הפיזור.
(3. אם כל הערכים של התכונה (אפשרויות) יוגדלו (יפחתו) במספר קבוע כלשהו A, אז השונות של האוכלוסייה החדשה לא תשתנה.
4. אם כל הערכים של התכונה (אפשרויות) מוגדלים (כפולים) ב-K פעמים, כאשר K הוא מספר קבוע, אז השונות של האוכלוסייה החדשה תגדל (תפחת) פי K 2.)
אנו מקבלים את הנוסחה לחישוב השונות בסדרות וריאציות במרווחים שווים בשיטת הרגעים:

A - אפס מותנה, שווה לאופציה עם התדר המקסימלי (אמצע המרווח עם התדר המקסימלי)
חישוב הממוצע בשיטת המומנטים מבוסס גם על השימוש בתכונות הממוצע.
![]()
הרעיון של התבוננות סלקטיבית. שלבי חקר תופעות כלכליות בשיטה סלקטיבית
מדגם הוא תצפית שבה לא כל יחידות האוכלוסייה הראשונית עוברות בחינה ולימוד, אלא רק חלק מהיחידות, בעוד שתוצאת הבדיקה של חלק מהאוכלוסייה משתרעת על כלל האוכלוסייה המקורית. הסט ממנו נקראת בחירת היחידות להמשך בחינה ולימוד כלליוכל האינדיקטורים המאפיינים סט זה נקראים כללי.
גבולות אפשריים של סטיות של ממוצע המדגם מהממוצע הכללי נקראים שגיאת דגימה.
קבוצת היחידות שנבחרו נקראת סֶלֶקטִיבִיוכל האינדיקטורים המאפיינים סט זה נקראים סֶלֶקטִיבִי.
מחקר סלקטיבי כולל את השלבים הבאים:
מאפייני מושא המחקר (תופעות כלכליות המוניות). אם האוכלוסייה הכללית קטנה, אזי דגימה לא מומלצת, יש צורך במחקר מתמשך;
חישוב גודל לדוגמה. חשוב לקבוע את הנפח האופטימלי שיאפשר, בעלות הנמוכה ביותר, לקבל שגיאת דגימה בטווח המקובל;
ביצוע בחירת יחידות תצפית, תוך התחשבות בדרישות של אקראיות, מידתיות.
עדות לייצוגיות המבוססת על אומדן של טעות דגימה. עבור מדגם אקראי, השגיאה מחושבת באמצעות נוסחאות. עבור מדגם היעד, ייצוגיות מוערכת באמצעות שיטות איכותניות (השוואה, ניסוי);
ניתוח מדגם. אם המדגם שנוצר עומד בדרישות הייצוגיות, הוא מנותח באמצעות אינדיקטורים אנליטיים (ממוצע, יחסי וכו')